Cross-Modal Visual-Tactile-Data-Generation
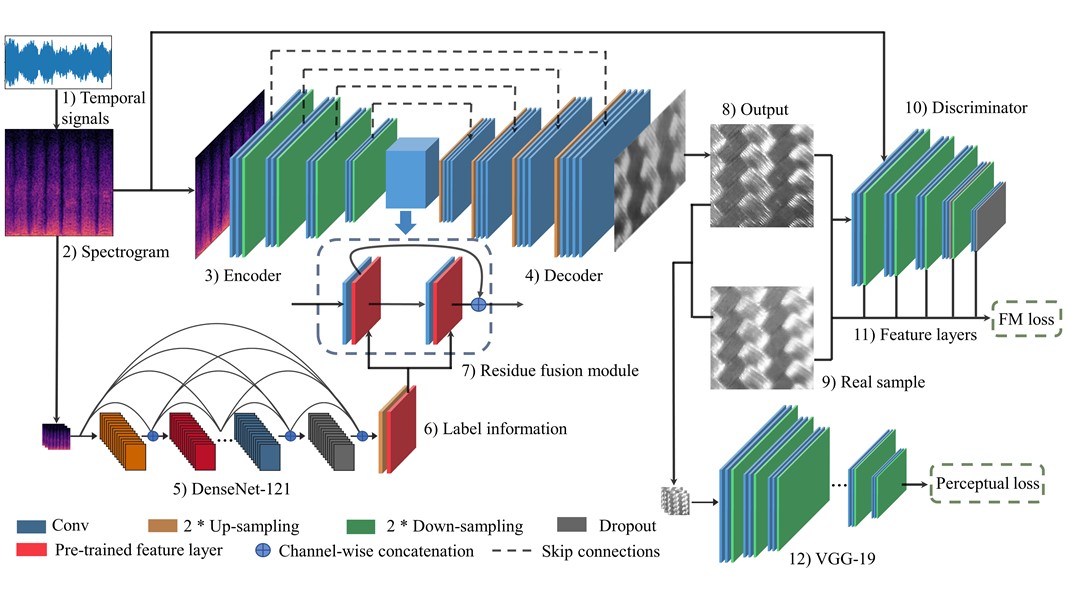
Existing psychophysical studies have revealed that the cross-modal visual-tactile perception is common for humans performing daily activities. However, it is still challenging to build the algorithmic mapping from one modality space to another, namely the cross-modal visual-tactile data translation/generation, which could be potentially important for robotic operation. In this paper, we propose a deep-learning-based approach for cross-modal visualtactile data generation by leveraging the framework of the generative adversarial networks (GANs). Our approach takes the visual image of a material surface as the visual data, and the accelerometer signal induced by the pen-sliding movement on the surface as the tactile data. We adopt the conditional-GAN (cGAN) structure together with the residue-fusion (RF) module, and train the model with the additional feature-matching (FM) and perceptual losses to achieve the cross-modal data generation. The experimental results show that the inclusion of the RF module, and the FM and the perceptual losses significantly improves cross-modal data generation performance in terms of the classification accuracy upon the generated data and the visual similarity between the ground-truth and the generated data.
Presented at IROS 2021 Conference
Authors: Shaoyu Cai, Kening Zhu, Yuki Ban, Takuji Narumi
Source code and data set: https://github.com/shaoyuca/Visual-Tactile-Data-Generation