CMVT
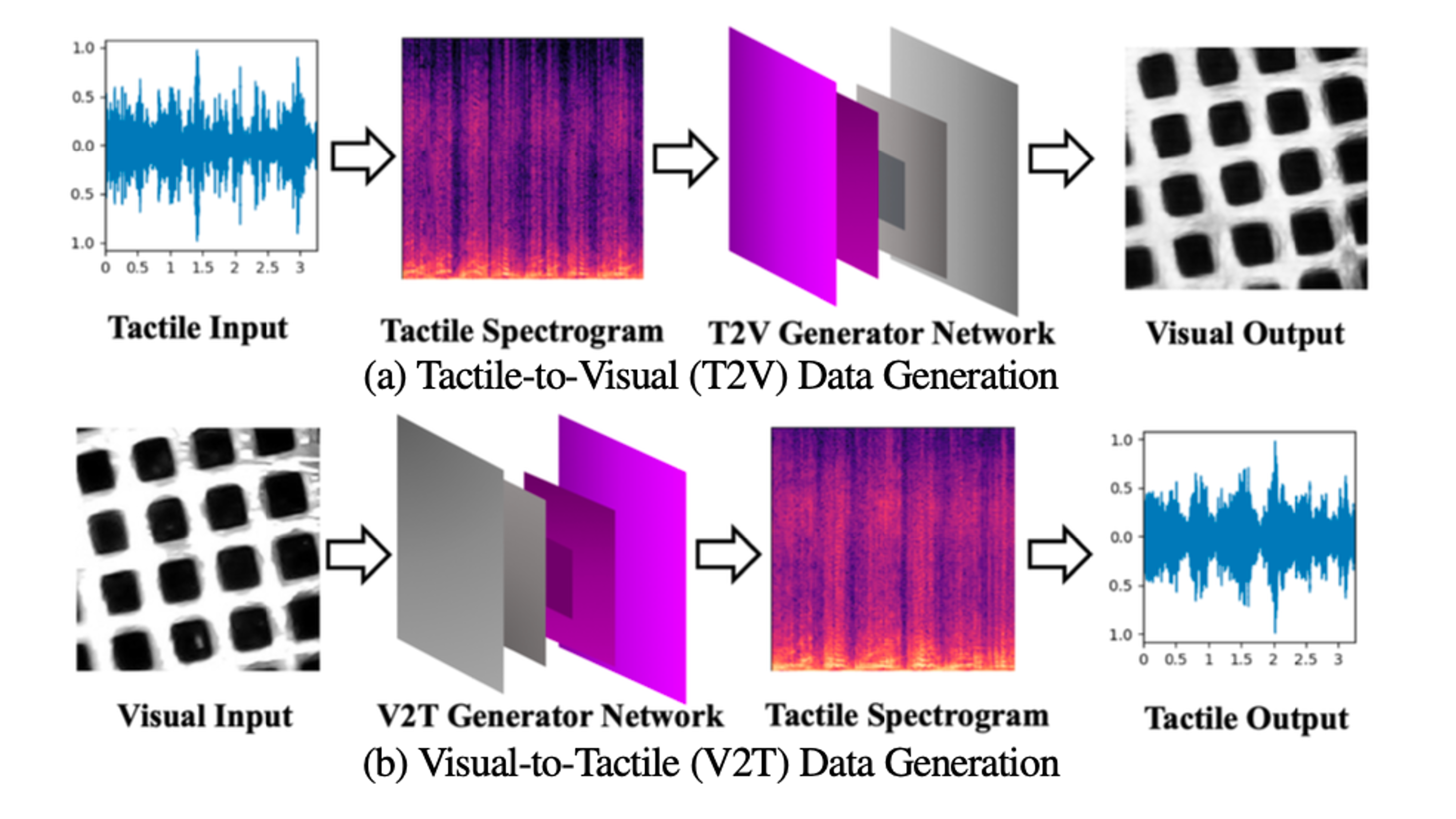
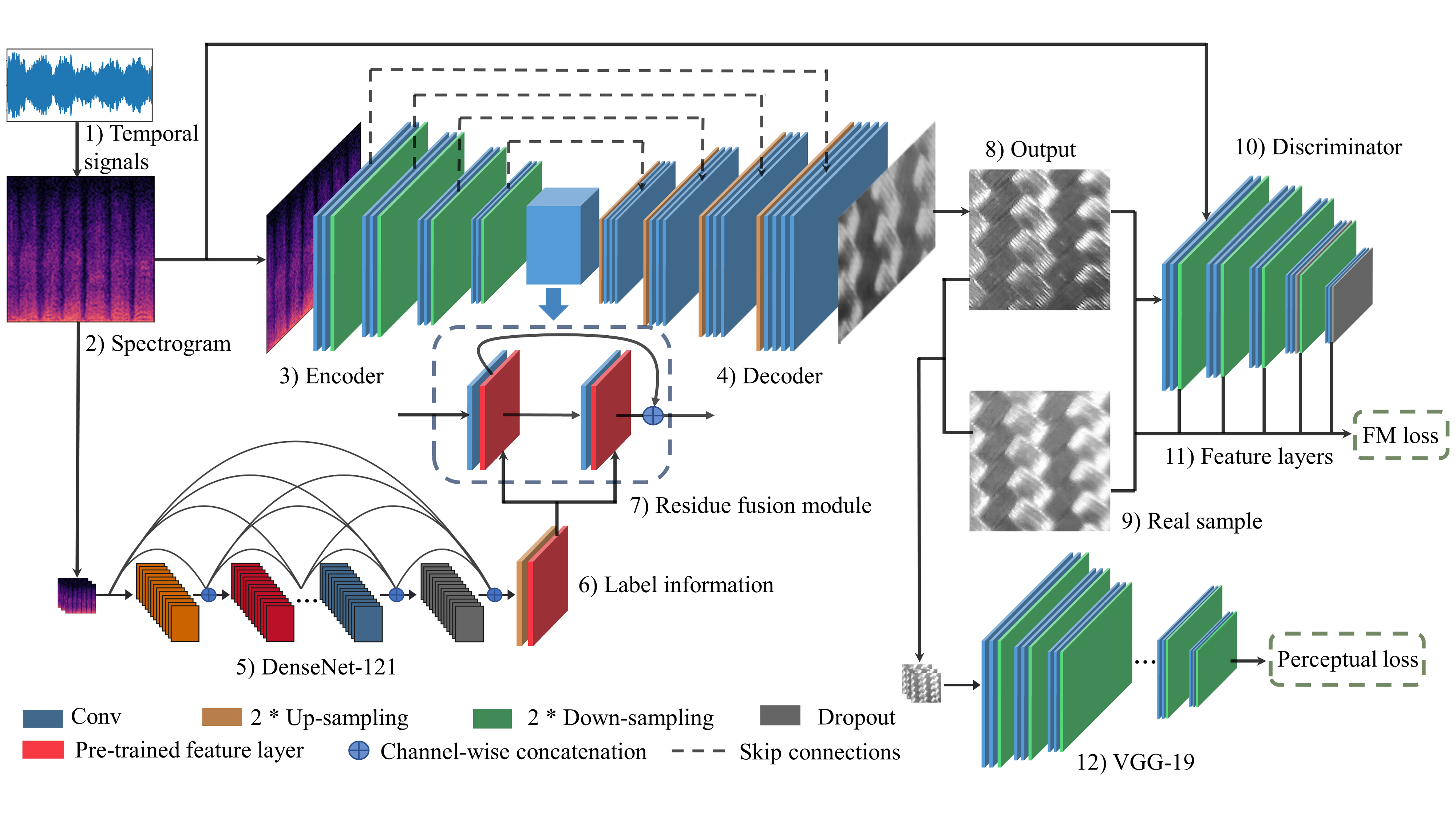
Existing psychophysical studies have revealed that the cross-modal visual-tactile perception is common for humans performing daily activities. However, it is still challenging to build the algorithmic mapping from one modality space to another, namely the cross-modal visual-tactile (CMVT) data translation/generation, which could be potentially important for robotic operation. CMVT studies visual-tactile cross-modal data generation for haptic texture simulation. The project uses a residue-fusion generative adversarial network with feature-matching and perceptual losses to generate tactile signals from visual texture information.
By learning relationships between what materials look like and how they may feel, the work supports scalable haptic content generation for virtual and augmented reality, reducing the need to manually record tactile data for every new material. Our approach could be potentially applied in various robotic operational tasks, such as object recognition in low-light conditions and light-weight object grasping.